
To make sense of any data it's often important to be able to connect it to the real world. When a vehicle sends its location to the server, it's important to be sure where the vehicle is actually located, even if the received information isn't perfect. The problem we'll tackle here is called map matching. Map matching (sometimes called road snapping) is a process of matching received vehicle coordinates with most likely road segment of a digital road map. Route reconstruction is a process of guessing the most probable route a vehicle traveled, based on received coordinates (and maybe some other factors).
The use of map matching (and usually more importantly, of route reconstruction) is wide, and if it wasn't such a difficult problem, it would be even wider. Personal bike riding logs as well as fleet tracking services, live traffic services and driving range estimations - all of them make use of it. And, finally, it's visually more appealing than a set of scattered points on a map.
Let's take a look at an example:
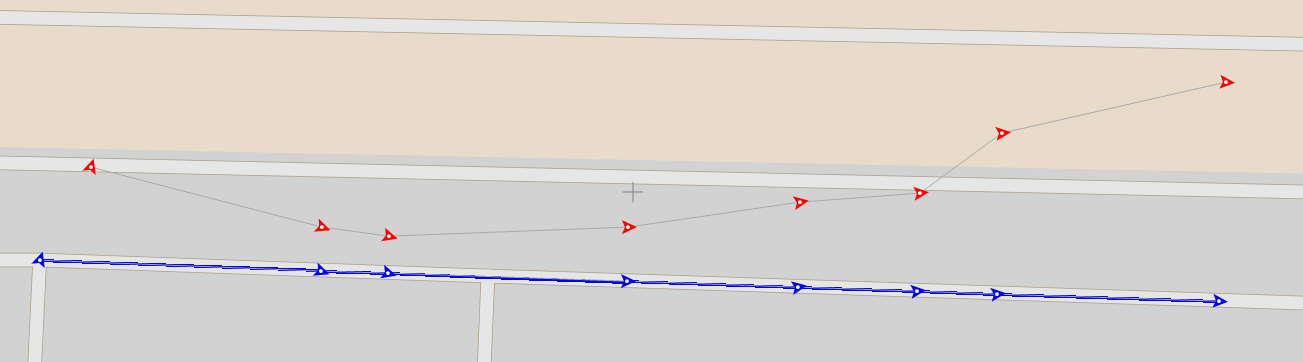
Red arrows in the image show the original GPS positions and the direction in which vehicle is moving, while the blue ones show the result of map matching and the lines connecting them show the result of route reconstruction algorithm. In real life, GPS location received from tracking devices is imprecise. The actual location normally varies a couple of meters, and it can be even more. This might happen for various reasons like small amount of visible satellites which overlap each other or signals bouncing off tall buildings around us. Devices usually provide this information along with other data in some form, usually just a number that the user should interpret. Estimated error in metres or just a grade could be something like "confidence", "precision", "accuracy" as a percentage.
The good measure of precision which is often used is called HDOP. HDOP is short for horizontal dilution of precision- a number telling us the confidence of the position we received. Without getting into details, the smaller this number is, the better. Ideal value is 0, values up to 5 are considered accurate, and values above20are considered very inaccurate. For example, we in Mireo ignore all positions with HDOP bigger than 20. For an interested reader, more about HDOP and other DOPs can be found here.
Another common set of problems is that sometimes it's impossible to have a good GPS position for the sole reason that there is no way our receiver can receive the position. Often because we are underground - in a garage, shopping mall or in a tunnel.Another common case is a vehicle being on a ferry, which can result in some very unusual/weird/uncommon observations/sensor readings (at once). A vehicle is travelling, but its engine isn't on, and it's not connected to any road(s).
With all that in mind, another key factor in map matching is the frequency of data. If the data is too sparse, it's hard (or even impossible) to determine vehicle's real position and its likely route. It sounds reasonable to expect for a vehicle to send the data as often as possible, but that introduces new problems. Some of them are data overload - servers need to process huge amounts of data while they could give the same results with less, This, introduces higher production costs, and as well a possibly slower result. Also, as data transfer is usually done via GPS carriers, the cost of sending the data nonstop could be unreasonably high.
Map matching is a computation-intensive task and often a stumbling block for most systems. Let's take a look at the general approaches usually considered in the standard literature to see why this is so:
- Geometric analysis focuses only on the geometry of the map and ignore the road connectivity. We can try matching our position to another point on the map (point-to-point), to a curve (point-to-curve) or even our trajectory to a curve (curve-to-curve). This method is the simplest and the fastest, but lacks in accuracy.
- Topological analysis takes road connectivity into consideration on top of geometrical analysis. Points are connected to the segment which best matches distance and orientation, only considering roads that are quickly reachable from the current segment.
- Probabilistic methods take position confidence into consideration as well as other factors mentioned previously. Such method might consider candidates within the error region of the position's precision (mentioned above), grade them based on their distance from the received point, direction (often called heading) relative to the road on which candidate lies and connectivity to the previous point.
Having all that in mind, we can see why map matching can be challenging. While computational geometry isn't something unheard of, it's still CPU intensive - calculating distances between points and curves, projections of points to the roads, closest points on a road and more surely takes some time. Doing that for several candidates, and evaluating them takes even more.
Let's consider the same image from the start of this article with additional points received:

The result in the first image might have looked erroneous as the northern road might be the better match for received positions - but further route reconstruction gave us a more probable result.
Here comes another important aspect of the map matching algorithm - is it working live(online) or offline?
In an offline mode, we can take our time to analyze a history of positions and reconstruct most probable locations and routes for a vehicle. While it is CPU intensive, it can be done in bulk (batches) with multiple processors. In that manner, by increasing the computational power of a system, we can solve this problem fairly well. However, there is a problem to consider - in this case a part of history either isn't available (it wasn't processed yet) or can be changed when it's processed. Both options, displaying vehicle's history or generating reports, have proven to be frustrating experiences.
In a live system which wants to display and use the matched data in (almost) real-time, the problem becomes more apparent. We cannot solve the problem in batches, we need to solve it as it happens, and it's even more so important to have a good algorithm and infrastructure supporting it. Taking us slightly back to the image above, if the route ended after first eight points, we could (and probably should) have taken the northern road as a result. As it's the case, this would have been wrong. Here comes a compromise - how fast do we consolidate the result in the balance of giving ourselves an option to "change our mind" and take the low road. Having the data available momentarily it's possible to use it to your advantage - creating real-time alarms, displaying at vehicle precisely on the map and generating consistent reports.
In Mireo, we do it live, with our own version of probabilistic method which uses our routing system, geometry, digital map and some more math. In our next blog we'll dive deeper into fine details of the process itself.
If you want to find more detailed information about the SpaceTime solution, visit our definitive guide through an unusual and fundamentally new approach of using spatiotemporal data in our everyday routine.