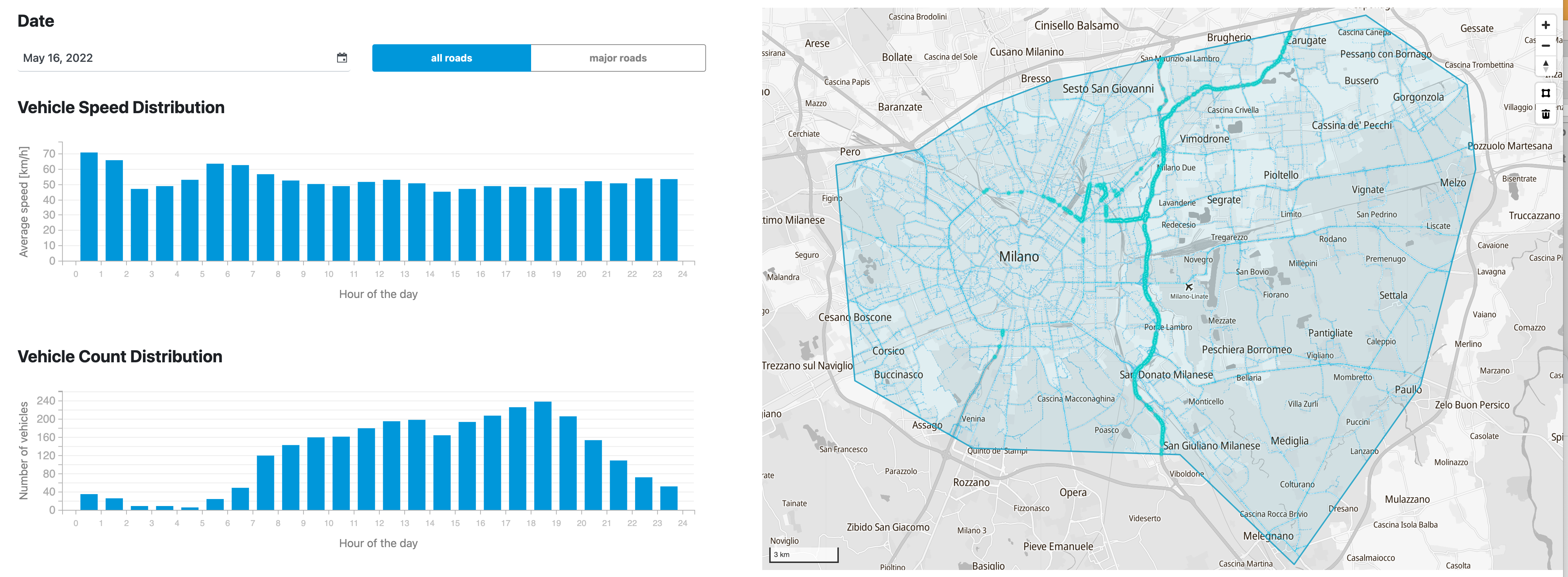
Geospatial databases, at a basic computer science and implementation level, are unrelated to more conventional databases. The surface similarities hide myriad design challenges that are specific to spatial data models.
J. Andrew Rogers, Why are Geospatial databases so hard to build?
In this blog post, we shall present Mireo SpaceTime – a massively scalable, distributed, disk-based storage and query execution engine designed for extremely fast insertion and querying of non-scalar data types. When applied to spatial or spatiotemporal data, the SpaceTime database provides unprecedented analytical tools speed, sometimes outperforming other state-of-the-art solutions by three orders of magnitude.
Someone may wonder why would a normal person create its own spatiotemporal database. In short, we were faced with the challenge of efficiently storing and searching an enormous amount of non-uniformly distributed spatiotemporal data continuously arriving from a large number of vehicles. It turned out that none of the off-the-shelf solutions were suitable for this task due to the pathological properties of their multidimensional indices. Detailed reasons that led us on the adventure of creating our own database can be found on the linked blog post.
SpaceTime database is a relational, horizontally scalable, SQL cloud database that possesses ACID (Atomicity, Consistency, Isolation and Durability) set of properties. Most modern databases are either relational or non-relational (NoSQL). However, SpaceTime belongs to the NewSQL class of databases which is a common name for the family of web-scale distributed relational SQL databases designed to overcome hard limitations of traditional SQL databases in the context of Big Data processing. A few notable members of NewSQL sort of DBMS are ClustrixDB, CockroachDB, VoltDB and MemSQL.