
One of the core markets served by Mireo software solutions is the Fleet management market. Among the requirements put on every fleet management software solution (FMS) is the capability of alarming users based on certain alarm raising criteria. In this two-part blog post, we'll share some info on ways in which we tackled the problem and the scalable, flexible and fast solution we came up with. Let's start by listing the requirements we were putting on our system.
Mireo SpaceTime spatiotemporal database is the backbone of our new FMS. To learn more about our new database, you can read this blog post. For the purpose of this post, it suffices to say that it is designed from the ground up to be a single point solution for collection and analysis of the massive amount of moving object data. In general, one of the critical requirements these systems have (and unfortunately the very one they almost always lack) is that they need to scale. Although we can use it for smaller-scale problems, the actual problem sizes for which Mireo SpaceTime was designed, and at which it performs best, are when the vehicle numbers measure in millions. We recognized that the whole vehicle tracking market is seeing strong consolidation trends in the current industry landscape. Also, the number of vehicles and devices equipped with GPS tracking capability is exploding so there is a strong need for solutions with which tracking of millions of vehicles is possible and comfortable. Subsequently, the cluster of machines that are ultimately doing all the work needs to be horizontally scalable. By extension, the solution we needed for alarm detection had to be scalable, hence our SW solution needed to be distributed. Although the scalability almost implies fault tolerance, this is also something of we had to keep in mind.
Due to the sheer data volume produced by millions of vehicles, our alarm detection solution also needed to be fast and efficient. To get the feeling about the amount of data we are dealing with here, let's assume we're collecting data from 3 million vehicles. A reasonable assumption is that these vehicles are reporting their position and equipment state every 3 seconds. This means that every single second, we need to process 1 million data records on the fly. After all, the users are expecting to be informed immediately when a particular alarm raises.
Apart from requirements that were mostly dictated by the vehicle fleet size of, there are a few more. Mireo FMS is a SaaS, and the fact that it is valid for almost every SaaS with the respectable user base (i.e., the need for covering a large number of use-cases) also holds for our FMS. For instance, one of the typical customer requirements is to be alarmed if a specific vehicle is speeding. On the other hand, they sometimes need to know if a vehicle driver has reached his working hour limit. Or maybe they want to know if someone is stealing the fuel from their 20-ton truck? The point here is that there is a great number of different alarm conditions, and it is impossible to know in advance all the use-cases the customers could need. Therefore, any solution we designed had to allow for easy addition and modification of alarm rules. That is how any code recompilation or redeployment when the need for new alarms arises, was ruled out.
Since we are in a business of geo-analytics, there is a large subset of alarms that are utilizing georeferenced data. The classical problem that is a part of this subset is the geofencing. For example, the customers often want to be informed when vehicles leave a specific predetermined area. The way this type of alarm is usually implemented is in the form of spatial database queries, which are notorious for being very inefficient if not correctly implemented. What we needed here was a mature and industry-proven solution.
When we summed up all of the above into a concise set of requirements, we got with the following list:
- we needed a fault-tolerant, scalable solution
- we needed to process data quickly and efficiently in real-time
- we needed simple addition/deletion of new alarms
- we needed support for geospatial queries
So how did we achieve this?
The overall system design that fits particularly well with most of our design requirements is the stream processing system. In this type of system, the stream is the fundamental data abstraction. We can define the stream as the continuously updated, unbounded sequence of data records. Each data record is represented by a key-value pair, and all operations on streams are performed by stream processors.
Let's make a small digression so we can better explain what services and utilities we already had at our disposal. As a messaging and IPC bus, the SpaceTime cluster uses the Kafka message queue. Below is a very simplified overview of our data processing pipeline.
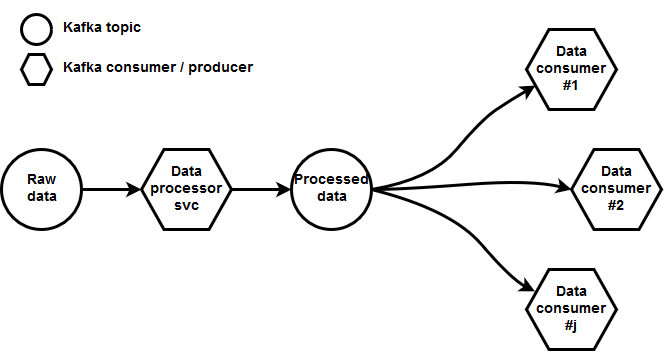
The vehicle tracking data enters in raw form. It then undergoes some fundamental yet very advanced data processing (e.g.,map matching). This process, in turn, feeds into processed data topic, which is the actual data entry point for all other data collection and analyzing service 1.
1Actually, the data processing service outputs to several different Kafka topics. For simplicity's sake, these processed data topics are shown here as a single Kafka topic, and for all aspects of this post, they can be regarded as immutable
The Kafka messaging queue, which had already been an integral part of our SpaceTime cluster, fits perfectly as the base of a stream processing system. The Kafka topics, in their essence, represent data streams by themselves. What is missing here is the functionality to perform stream operations. The most powerful operation we can perform on a stream is stream transformation. We can transform each stream into some other stream, either by filtering, mapping, aggregating stream data, decorating with some other static data or even by joining the original stream with other streams.
This concept is well known, and since Kafka fits into it very well, it comes as no surprise that there is a platform that already utilizes Kafka capabilities and extends on them. The platform is called Confluent. It is managed by some of the Kafka creators and is actually on a steep rise at the moment. Unfortunately, there are some aspects of this solution which made it inappropriate for our use-case. Namely, the support for georeferenced queries in KSQL, the Confluent stream querying language, is currently rudimentary at best. Moreover, the indexing is by design only possible on data record keys, and there are certain types of queries we needed, which would be performance killers on data sets indexed only in this way.
We had to look elsewhere, and since we didn't find shelf solutions, we had to come with our own. In part two of this blog, we will describe how, by incorporating some well known and proven libraries, we came up with a solution that met all of our requirements.

